




This Blog provides code for scraping APEX Classic Reports & Interactive Reports on public pages (It does not log in - it just scrapes). There are all kinds of Templates, Pagination styles & Report Types out there i.e. IR, IG, Cards, Reflow, etc. Each provides their own scraping challenge. Should I find a case for scraping something other than basic Classic & Interactive Reports, I'll update this blog with the code.
You might have seen my blog that I wrote for #JoelKallmanDay regarding scraping Beer stores for deals and storing the results in APEX.
That blog essentially is about scraping sites built with Shopify. But how can I scrape data from APEX pages, specifically Classic Reports with pagination and unknown page count, then export results as JSON, when download links are unavailable?
Scrapy the best web scraping tool around. Using Scrapy, you can build and run web scraping spiders with it.
APEX Pagination presents a challenge as, unlike in the Shopify example, its not a link to a page containing the next set of results. Instead, the next page button triggers a dynamic partial page refresh. However, Scrapy does not have the ability to click buttons or run JavaScript, but Selenium has. However Selenium wasn't playing ball with dynamic changing regions, so I found something else that worked rather well. This is called Beautiful Soup.
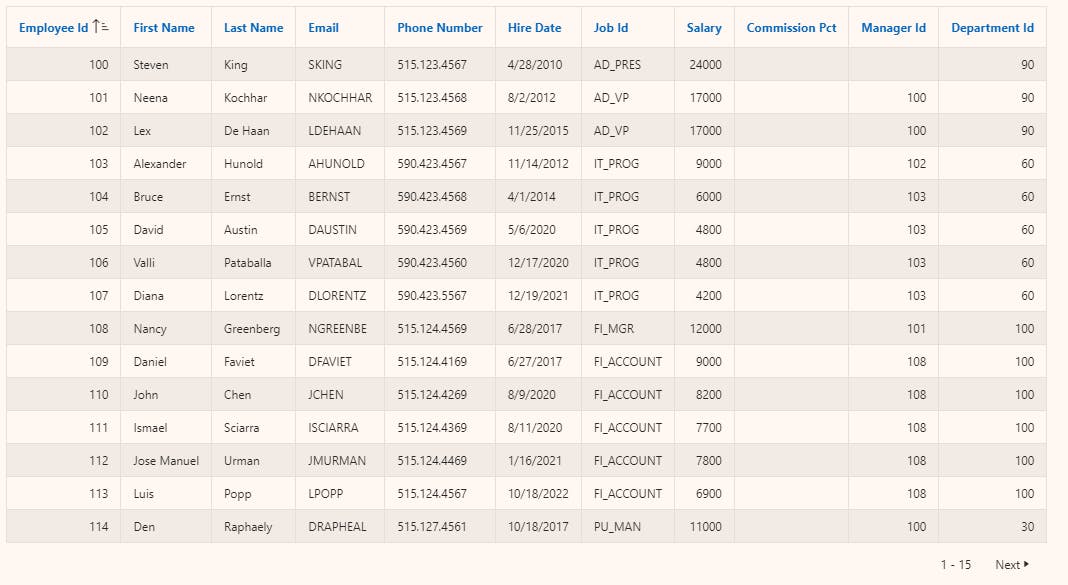
After following the steps below, I manage to scrap the entire report under a minute, including all paginated pages into my output.json file. Here are the last two records (as proof) which were on the very last report page.
Before continuing, read this article on webscraping.fyi to check (1) your country's specific laws and (2) The bullet point criteria is met.
Also note that many APEX sites, Cloud included, contain a robots.txt file which may request clients not to scrape. By Default, Scrapy obeys this request.
Steps
Follow these Install Scrapy For Oracle Unix or WSL steps.
Note I installed this Oracle Linux 8.8 WSL image into Windows to work on Scrapy projects. Then I just typewslinto a dos box and I'm working in my WSL.Install dependencies
pip install beautifulsoup4 pip install selenium sudo yum install epel-release sudo yum-config-manager --enable ol8_developer_EPEL sudo yum install chromium -yStart a project. I'm calling mine apexreports
scrapy startproject apexreportsOpen VSCode and open the newly created apexreports folder.
Windows users: Make sure you switch to your WSL
Not Advisable: Open the settings.py file and change the ROBOTSTXT_OBEY to False😱. This is because some APEX sites, Cloud included, instruct Scrapy not to scrape. Unless told otherwise, Scrapy obeys the robots.txt file.
# Obey robots.txt rules ROBOTSTXT_OBEY = FalseCreate a new file in the spiders folder called /spiders/apex_report_spider.py (or change as appropriate)
Paste in the Scrapy code from the APEX Report Scrapy Code section below
Customize the code by following the Customization Instructions within the same section.
Run the spider
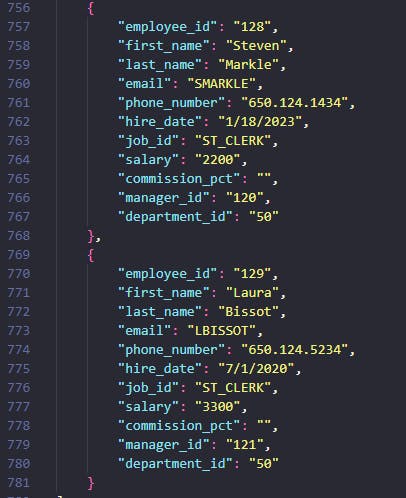
scrapy crawl apex_report_spider -O output.json(Optional) Inspect the log. You can see I've scraped 107 items
2024-01-05 22:22:28 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 1001, 'downloader/request_count': 3, 'downloader/request_method_count/GET': 3, 'downloader/response_bytes': 27529, 'downloader/response_count': 3, 'downloader/response_status_count/200': 1, 'downloader/response_status_count/302': 2, 'elapsed_time_seconds': 37.743575, 'feedexport/success_count/FileFeedStorage': 1, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2024, 1, 5, 21, 22, 28, 604355, tzinfo=datetime.timezone.utc), 'item_scraped_count': 107, 'log_count/DEBUG': 281, 'log_count/INFO': 11, 'memusage/max': 68157440, 'memusage/startup': 68157440, 'response_received_count': 1, 'scheduler/dequeued': 3, 'scheduler/dequeued/memory': 3, 'scheduler/enqueued': 3, 'scheduler/enqueued/memory': 3, 'start_time': datetime.datetime(2024, 1, 5, 21, 21, 50, 860780, tzinfo=datetime.timezone.utc)} 2024-01-05 22:22:28 [scrapy.core.engine] INFO: Spider closed (finished)Inspect the output.json file
Load the scraped results from JSON into APEX
This blog doesn't go into these details. However I recommend reading the two links below and customizing the steps as appropriate.
APEX Report Scrapy Code
Customization Instructions
start_urls: (Mandatory) You must add a start URL
apex_report_type: (Mandatory) CR (Classic Report) and IR (Interactive Report) are supported
report_static_id: (Optional) Leave blank unless you want to scrape a single specific report on the page
sleep(4): Leave it as is, or experiment with it. With it removed, the report may not have time to refresh and records may be scraped more than once.
Code
import scrapy
from scrapy.http import HtmlResponse
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException, StaleElementReferenceException
from time import sleep
class ApexIdeasSpider(scrapy.Spider):
name = 'apex_report_spider'
start_urls = [''] # e.g. https://abc.adb.eu-frankfurt-1.oraclecloudapps.com/ords/r/lufc/scrape-me
apex_report_type = 'CR' # e.g. CR or IR
report_static_id = '' # e.g. #R34821968408206237
def __init__(self):
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--no-sandbox')
self.driver = webdriver.Chrome(options=chrome_options)
if self.apex_report_type == 'CR':
self.sel_headers = 'table.t-Report-report thead th'
self.sel_rows = 'table.t-Report-report tbody tr'
self.sel_next = 'a.t-Report-paginationLink--next'
elif self.apex_report_type == 'IR':
self.sel_headers = 'div.t-fht-thead table.a-IRR-table th.a-IRR-header'
self.sel_rows = 'div.t-fht-tbody table.a-IRR-table tbody tr:not(:first-child)'
self.sel_next = 'button.a-IRR-button--pagination[title="Next"]'
else:
raise ValueError("Invalid apex_report_type: {}".format(self.apex_report_type)) # Handle invalid type
def parse(self, response):
self.driver.get(response.url)
# Extract header names dynamically
soup = BeautifulSoup(self.driver.page_source, 'html.parser')
headers = [th['id'] for th in soup.select(f"{self.report_static_id} {self.sel_headers}")]
while True: # Loop until no more pagination buttons
soup = BeautifulSoup(self.driver.page_source, 'html.parser')
rows = soup.select( f"{self.report_static_id} {self.sel_rows}")
for row in rows:
data = {}
for idx, header in enumerate(headers):
cell_value = row.select_one(f'td[headers="{header}"]')
cell_value = cell_value.text.strip()
data[header.lower()] = cell_value
yield data
try:
next_button = WebDriverWait(self.driver, 5).until(
EC.presence_of_element_located((By.CSS_SELECTOR, f"{self.report_static_id} {self.sel_next}"))
)
except TimeoutException:
break # No more pagination buttons, exit the loop gracefully
if next_button:
next_button.click()
sleep(4)
# Wait for pagination to complete (adjust condition if needed)
WebDriverWait(self.driver, 5).until(
EC.presence_of_element_located((By.CSS_SELECTOR, f"{self.report_static_id} {self.sel_rows}"))
)
else:
break # No more pagination buttons, exit the loop
def closed(self, reason):
self.driver.quit()
Conclusion
ENJOY!
Whats the picture? It's Knaresborough. Visit Yorkshire!